Crowdsourcing Multimodal Dialog Interactions

Crowdsourcing has emerged as one of the most popular methods of collecting spoken, video and text data over the last few years. We have focused on the collection, development and testing of interactions between a human and an automated dialog system using crowdsourcing methods. The data collection leverages a set of goal-oriented conversational tasks developed for English language learners to provide speaking practice for non-native speakers of English across a wide range of common linguistic functions in a workplace environment. In addition, the tasks are designed to be able to provide feedback to the language learners about whether they have used the required linguistic skills to complete the task successfully. The map on the left shows a geographical distribution of callers into the HALEF dialog system from all over the world. Hotter colors (closer to deep red) indicate a higher density of callers.
For more details, please see:
Vikram Ramanarayanan, Patrick Lange, Keelan Evanini, Hillary Molloy, Eugene Tsuprun and David Suendermann-Oeft (2017). Crowdsourcing multimodal dialog interactions: Lessons learned from the HALEF case, in proceedings of: American Association of Artificial Intelligence (AAAI) 2017 Workshop on Crowdsourcing, Deep Learning and Artificial Intelligence Agents, San Francisco, CA, Feb 2017 [pdf].
Real-time MRI of Speech Production
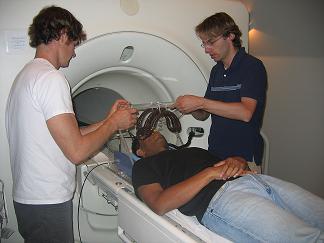
The speech production (SPAN) group at USC has pioneered the use of real-time magnetic resonance imaging to study speech production. This includes development of custom hardware and software to record videos of speech production that contain synchronized, noise-cancelled audio. The photo on the left shows experimenters preparing a subject for a scan and setting up a custom 4-channel receive coil with an attached optical microphone setup to collect video data (photo credits: Erik Bresch).
My contributions included serving as an audio operator, helping with the experimental setup, postprocessing acquired data, and maintaining the database of articulatory data.
Speech Enhancement of Noisy MRI audio
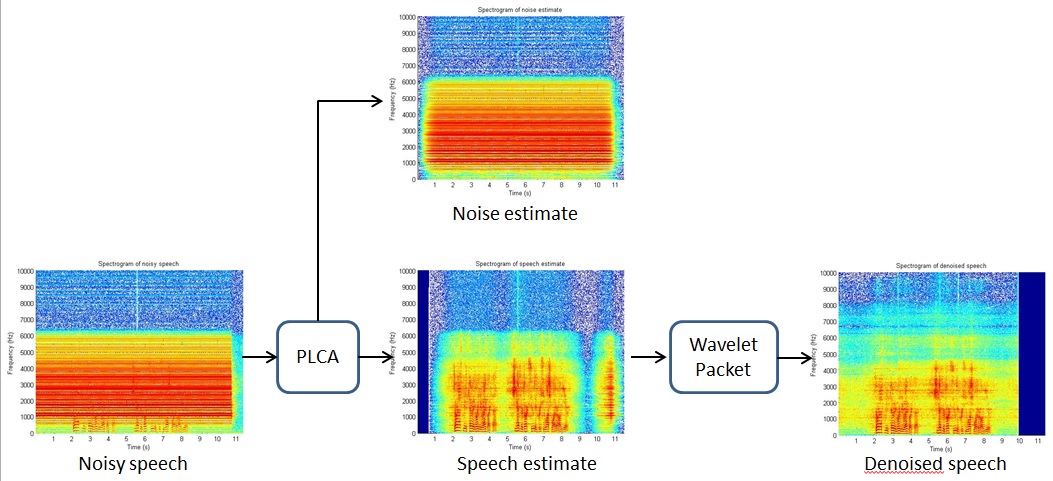
MRI scanners produce high-energy broadband noise that corrupts the speech recording. This affects the ability to analyze the speech acoustics resulting from the articulation and requires additional schemes to improve the audio quality.
We designed a method for speech enhancement of data collected in extremely noisy environments, such as those found during magnetic resonance imaging (MRI) scans. We propose a two-step algorithm to perform this noise suppression. First, we use probabilistic latent component analysis to learn dictionaries of the noise and speech+noise portions of the data and use these to factor the noisy spectrum into estimated speech and noise components. Second, we apply a wavelet packet analysis in conjunction with a wavelet threshold that minimizes the KL divergence between the estimated speech and noise to achieve further noise suppression. Based on both objective and subjective assessments, we find that our algorithm significantly outperforms traditional techniques such as nLMS, while not requiring prior knowledge or periodicity of the noise waveforms that current state-of-the-art algorithms require.
For more details, please see:
Colin Vaz, Vikram Ramanarayanan and Shrikanth Narayanan (2013). A two-step technique for MRI audio enhancement using dictionary learning and wavelet packet analysis, in proceedings of: Interspeech 2013, Lyon, France, Aug 2013 [pdf]. (Best Student Paper Award)
Collection of Video Data from Classrooms

We designed and implemented a protocol to record and analyze audiovisual data of engagement behavior observed during instructional classroom sessions. We used a single-camcorder setup to capture audio-visual data in a setting offering informal, after-school science learning experiences for young children and their families. The recording setup has the advantage that it is simple, portable and easily available (and hence easily replicable) allowing ecologically-valid observations. We further set up a YouTube-based system for different experts to annotate video, and software code to automatically collate this information for further analysis. Since these videos contain a “bird’s eye” view of the classroom, our tools were designed to allow the annotators to pin-point the event of interest both in space and time.