Multimodal Presentation Scoring
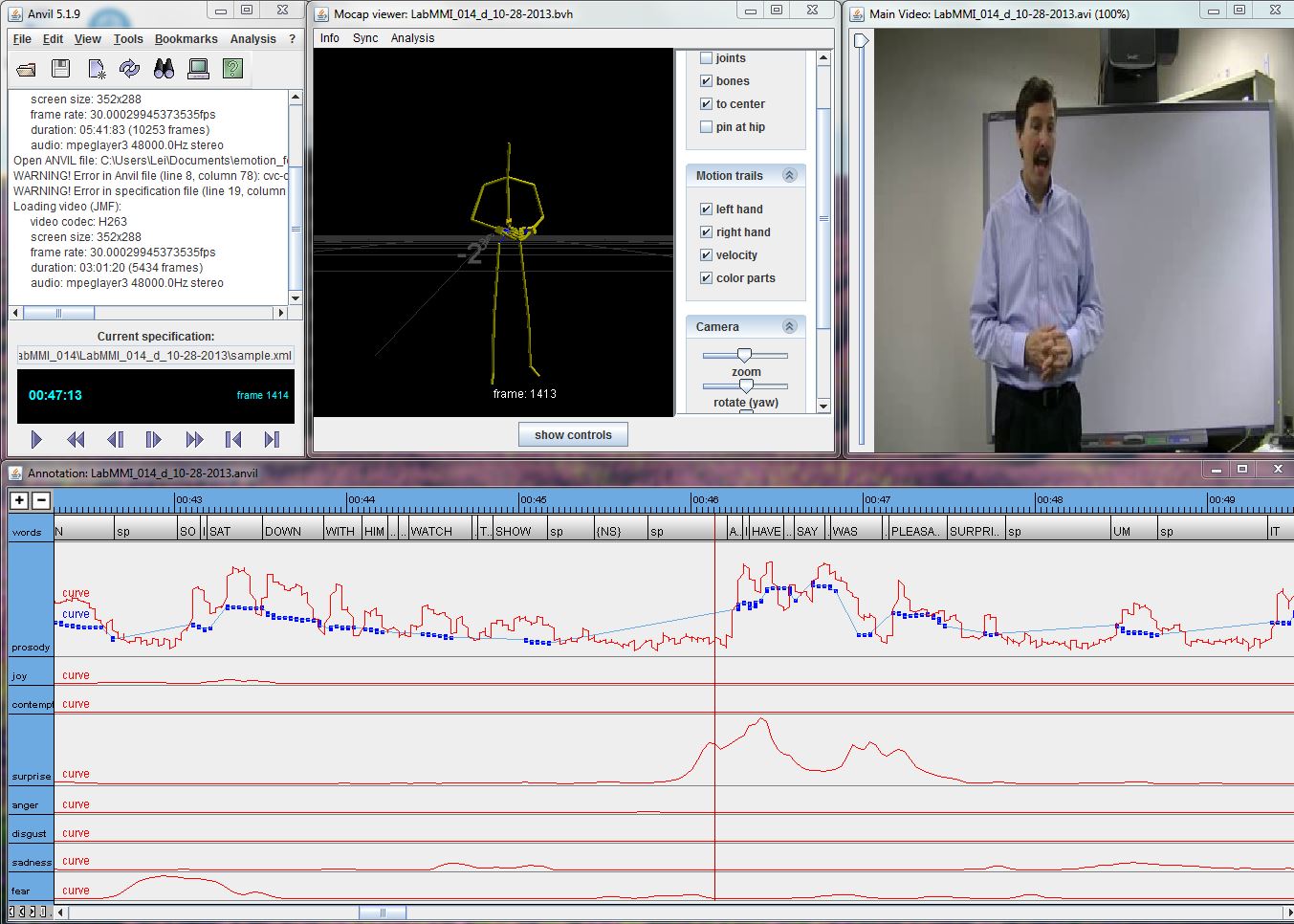
We analyze how fusing features obtained from different multimodal data streams such as speech, face, body movement and emotion tracks can be applied to the scoring of multimodal presentations. We compute both time-aggregated and time-series based features from these data streams – the former being statistical functionals and other cumulative features computed over the entire time series, while the latter, dubbed histograms of cooccurrences, capture how different prototypical body posture or facial configurations co-occur within different time- lags of each other over the evolution of the multimodal, multivariate time series. We examine the relative utility of these features, along with curated speech stream features in predicting human-rated scores of multiple aspects of presentation proficiency. We find that different modalities are useful in predicting different aspects, even outperforming a naive human inter-rater agreement baseline for a subset of the aspects analyzed.
Vikram Ramanarayanan, Chee Wee Leong, Lei Chen, Gary Feng and David Suendermann-Oeft (2015). Evaluating speech, face, emotion and body movement time-series features for automated multimodal presentation scoring, in proceedings of: International Conference on Multimodal Interaction (ICMI 2015), Seattle, WA, Nov 2015 [pdf].
Vikram Ramanarayanan, Lei Chen, Chee Wee Leong, Gary Feng and David Suendermann-Oeft (2015). An analysis of time-aggregated and time-series features for scoring different aspects of multimodal presentation data, in proceedings of: Interspeech 2015, Dresden, Germany, Sept 2015 [pdf].
Unusual Event Detection in Classroom Video

We designed a framework to record and analyze audiovisual data of participant engagement behavior observed during instructional classroom sessions. We used a simple and portable single-camcorder setup to record approximately sessions of audio-visual data in a setting offering informal, after-school science learning experiences for young children and their families.
We split the task of video analysis into two phases – an initial data annotation phase followed by an automated analysis phase. For the first phase, we asked experts to annotate the videos for different examples of engagement (or any kind of constructive behavior that educators would like to encourage in classroom interactions) and disengagement behavior (for example, see adjacent figure). The second phase involves using the annotated data to detect these unusual behaviors. We envision such an effort will aid the process of classroom instruction, by providing instructors with a tool to assess classroom response (for e.g., engagement or disengagement) to the instruction, thus facilitating the teaching process and increasing the efficacy of the learning process.
Vikram Ramanarayanan, Naveen Kumar and Shrikanth S. Narayanan (2012), A framework for unusual event detection in videos of informal classroom settings, in: NIPS 2012 workshop on Personalizing Education with Machine Learning, Lake Tahoe, NV, Dec 2012 [pdf].
Child Reading Comprehension Analytics

Rapid Automatized Naming (RAN) is a powerful tool for predicting future reading skill. A person’s ability to quickly name symbols as they scan a table (see the figure on left, for example) is related to higher-level reading proficiency in adults and is predictive of future literacy gains in children. However, noticeable differences are present in the strategies or patterns within groups having similar task completion times. Thus, a further stratification of RAN dynamics may lead to better characterization and later intervention to support reading skill acquisition.
In this work, we analyze the dynamics of the eyes, voice, and the coordination between the two during performance. It is shown that fast performers are more similar to each other than to slow performers in their patterns, but not vice-versa. Further insights are provided about the patterns of more proficient subjects. For instance, fast performers tended to exhibit smoother behavior contours, suggesting a more stable perception-production process.
For more details, please refer to:
Daniel Bone, Chi-Chun Lee, Vikram Ramanarayanan, Shrikanth Narayanan, Renske S. Hoedemaker and Peter C. Gordon (2013). Analyzing eye-voice coordination in Rapid Automatized Naming, in proceedings of: Interspeech 2013, Lyon, France, Aug 2013 [pdf].