Exploiting Speech Production Knowledge for Speech Technology Applications

In the overview article cited below, we review the potential for incorporating direct (such as those shown in the table), or inferred, speech production knowledge in speech technology development. We review the technologies that can be used to capture speech articulation information, and discuss how meaningful (speech and speaker) representations can be derived from articulatory data thus captured and further how they can be estimated from the acoustics in the absence of these direct measurements. We present some applications that have used speech production information to further the state of the art in automatic speech and speaker recognition. We also offer an outlook on how such knowledge and applications can in turn inform scientific understanding of the human speech communication process.
Vikram Ramanarayanan, Prasanta Ghosh, Adam Lammert and Shrikanth S. Narayanan (2012), Exploiting speech production information for automatic speech and speaker modeling and recognition – possibilities and new opportunities , in proceedings of: APSIPA 2012, Los Angeles, CA, Dec 2012 [pdf].
Extracting Discriminative Information from Speech
The speech signal at the acoustic level has a much higher bit rate (e.g., 64 kbits/sec assuming 8 kHz sampling rate and 8 bits/sample encoding) as compared to that of the underlying sound patterns that have an information rate of less than a 100 bits/sec (Atal, 1999). The presence of this large redundancy in the speech signal means that we first need to extract a lower-dimensional representation of the signal that best captures the discriminative information required for a given task at hand. For example, in the case of a phone discrimination task, we would want to extract a representation that is able to capture the differences between various sounds in a language.
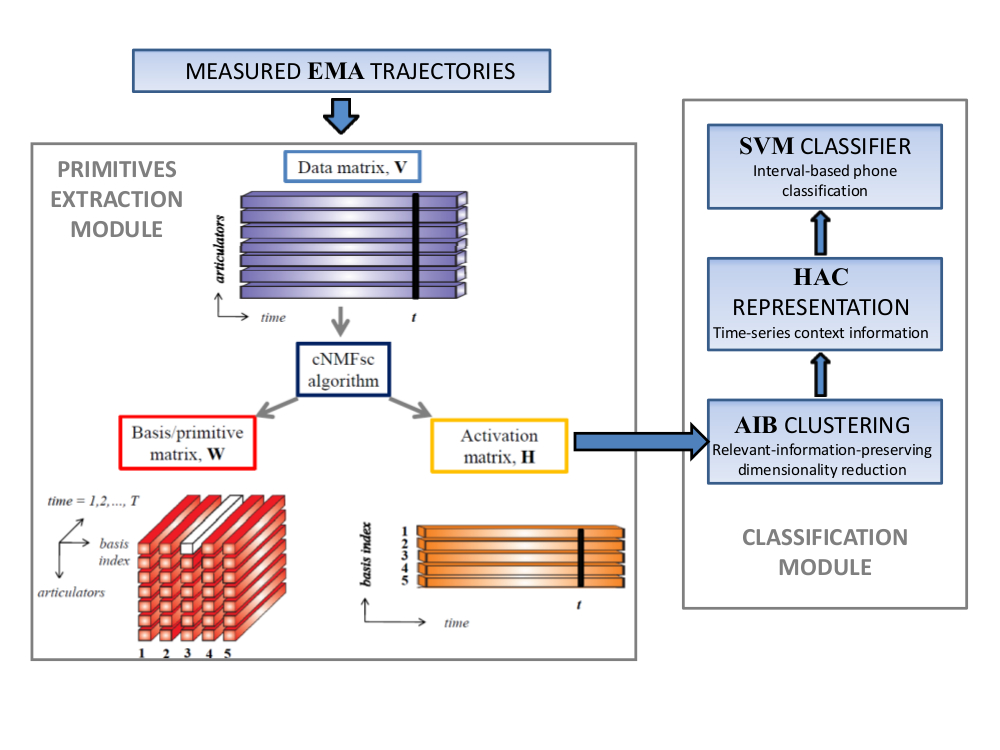
In this work we explore the nature of low dimensional representations derived directly from articulatory signals based on sparsity constraints. Specifically, we present a method to examine how well derived representations of ‘‘primitive movements’’ of speech articulation can be used to classify broad phone categories (see setup on left). We show that this feature, derived entirely from activations of these primitive movements, is able to achieve an accuracy of about 80% on an interval-based phone classification task.
For more details, please refer to:
Vikram Ramanarayanan, Maarten Van Segbroeck, and Shrikanth S. Narayanan (2015), Directly data-derived articulatory gesture-like representations retain discriminatory information about phone categories, in: Computer Speech and Language. [link]
Vikram Ramanarayanan, Maarten Van Segbroeck and Shrikanth Narayanan (2013). On the nature of data-driven primitive representations of speech articulation, in proceedings of: Interspeech 2013 Workshop on Speech Production in Automatic Speech Recognition (SPASR), Lyon, France, Aug 2013 [pdf].
Speaker Recognition

We proposed a practical, feature-level fusion approach for speaker verification using information from both acoustic and articulatory signals. We found that concatenating articulation features obtained from actual speech production data with conventional Mel-frequency cepstral coefficients (MFCCs) improved the overall speaker verification performance.
However, since access to actual speech production data is impractical for real world speaker verification applications, we also experimented with acoustic-to-articulatory inversion techniques for estimating articulatory information. Specifically, we showed that augmenting MFCCs with features obtained from subject-independent acoustic-to-articulatory inversion techniques also significantly enhanced the speaker verification performance. Experimental results on the Wisconsin X-Ray Microbeam database showed that the proposed speech-and-inverted-articulation fusion approach significantly outperformed the traditional speech-only baseline, providing up to 10% relative reduction in Equal Error Rate (EER) (see figure on left).
For more details, please see:
Ming Li, Jangwon Kim, Prasanta Ghosh, Vikram Ramanarayanan and Shrikanth Narayanan (2013). Speaker verification based on fusion of acoustic and articulatory information, in proceedings of: Interspeech 2013, Lyon, France, Aug 2013 [pdf].
Articulatory Recognition

Real-time MRI is a rich source of information for the entire vocal tract and not only for certain articulatory landmarks and further has the potential to continue increasing in size covering a large variety of speakers and speaking styles. In this work, we investigated an articulatory representation based on full vocal tract shapes. We employed an articulatory recognition framework to analyze its merits and drawbacks. We argue that articulatory recognition can serve as a general validation tool for real-time MRI based articulatory representations.
For more details, please refer to:
Athanasios Katsamanis, Erik Bresch, Vikram Ramanarayanan and Shrikanth Narayanan (2011). Validating rt-MRI based articulatory representations via articulatory recognition, in proceedings of: Interspeech 2011, Florence, Italy, Aug 2011 [pdf].